Understanding Data Extraction for Receipts and Invoices
Explore how OCR, NLP, and machine learning work together to extract data from receipts and invoices.
This page covers the core technologies behind accurate document automation.
The Foundation: OCR
Optical Character Recognition (OCR) is the fundamental technology that converts various document types—scanned papers, PDFs, or images—into machine-readable text. For receipt and invoice processing, OCR is the crucial first step in transforming both physical and digital documents into structured, actionable data.
Beyond Traditional OCR
While OCR technology dates back to the 1960s, modern document processing engines like Taggun far extends its capabilities:
OCR as the Starting Point:
- Converts image-based text into machine-readable format.
- Provides the raw textual data for further processing.
Natural Language Processing (NLP):
- Analyses the OCR output to understand context and meaning.
- Enables interpretation of the extracted text, not just recognition.
By combining OCR and NLP, document processing systems can:
- Extract structured data from unstructured documents.
- Understand the relationships between different pieces of information.
- Adapt to various document layouts and formats.
- Handle complex scenarios such as multi-language documents or ambiguous data.
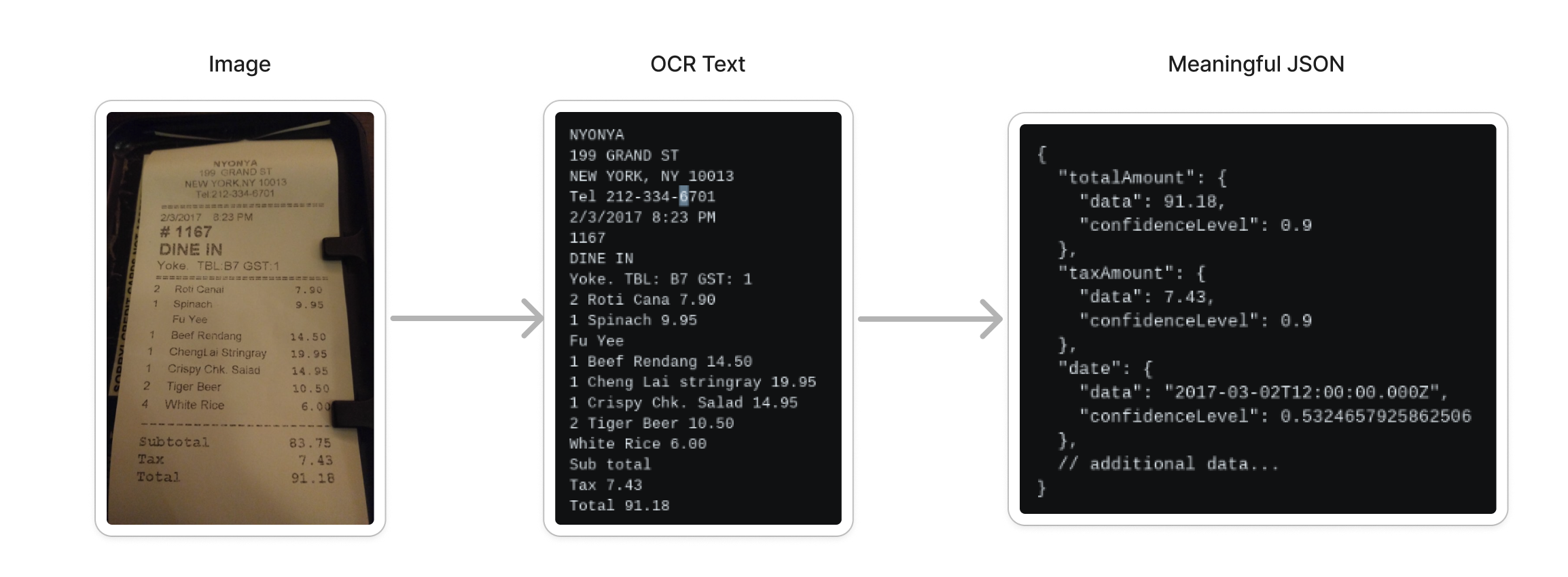
Fundamental OCR Process
Taggun's Data Extraction Process
- Pre-Processing:
- Enhance image quality through cleaning, noise reduction and brightness adjustment.
- Detect document format to optimise OCR settings.
- Text Extraction (OCR):
- Convert images and PDFs into clear, accurate text data.
- Understanding (NLP):
- Identify key details like product descriptions, totals and taxes.
- Adapt to various formats and languages, from English to Mandarin.
- Assigns confidence levels to indicate the likelihood of accuracy.
- Precise Data Mapping:
- Organise extracted information into structured formats.
- Map line items, subtotals, taxes, and other relevant data.
- Ensure all important data points are captured for easy integration.
- Post-Processing:
- Validate data for consistency and correct errors.
- Refine ambiguities to improve accuracy.
- Run advanced processing: validate tax IDs, standardise date formats and currencies, detect fraud, categorise expenses, apply custom rules, and more.
- Developer-Friendly Output:
- Deliver standardised, clean JSON format for easy integration.
- Ongoing Optimisation:
- Continuously improve through machine learning.
- Fine-tune models based on processed documents.
- Adapt to new formats and languages over time.
Overcoming Complex Challenges
Taggun's system tackles difficult scenarios with ease:
- Multi-Format, Multi-Language: Adapts to various document layouts and languages.
- Low-Quality Images: Extracts data effectively even from poor-quality photos or crumpled documents.
- Long Receipt Processing: Efficiently handles extended receipts with numerous line items, maintaining accuracy throughout the entire document.
- Ambiguity Resolution: Interprets unclear data that traditional OCR can't handle.
- Handwriting Recognition: Accurately processes handwritten elements on receipts and invoices.
Taggun's Multi-Model Approach
Taggun employs a multi-model system where different machine learning models work together at every stage of the data extraction process, ensuring high accuracy and adaptability across various document types. Each stage has its own set of specialised models:
- Text Recognition (OCR) Models:
Multiple models handle different aspects of text extraction, such as detecting printed text, handwritten text, and low-quality or skewed images. These models ensure that even poorly scanned documents are processed with high accuracy.
- Natural Language Processing (NLP) Models:
At this stage, several NLP models work in tandem to understand the context of the extracted text. One model might identify product names, while another focuses on recognising prices, taxes, and dates. Together, they ensure that key financial information is accurately understood, regardless of language or format.
- Data Structuring Models:
Once the data is extracted and understood, multiple models map this information into structured formats like line items, subtotals, and tax categories. Different models handle different document layouts and formats, ensuring consistent data mapping, whether it's a short receipt or a long, multi-item invoice.
These models work together in a multi-layered system, allowing Taggun to handle a wide range of documents, from high-quality digital invoices to low-resolution scanned receipts, in 205 languages and formats. This multi-model approach significantly enhances the accuracy, flexibility, and reliability of our system.
Continuous Improvement Through Machine Learning
Taggun's machine learning system continuously refines its document processing capabilities. Typically, this process is highly resource-intensive and more complex than initially apparent. It demands significant computational power, time, and specialised expertise to develop and maintain effectively.
- Evolving Models: Constantly refine accuracy using extensive receipt and invoice datasets.
- Adaptive Processing: Quickly adjusts to new document formats and styles.
Advanced Features:
Taggun has advanced processing layers to automate additional tasks beyond basic data extraction, including but not limited to:
- Fraud Detection: Automatically flags suspicious receipts.
- Purchase Categorisation: Auto-sorts expenses to match your specific needs.
- Global Capabilities: Processes receipts worldwide, adapting to local formats.
- Custom Validation: Set your own rules for data accuracy and validity.
Customisation
- We offer flexible customisation support, including tailored fields, formats, and localised support.
- Expand into new markets confidently with our adaptable technology.
- We fully manage accuracy optimisation, so you don't have to.
In Summary
Taggun goes far beyond traditional receipt OCR.
We give you a comprehensive, customisable toolset for receipt and invoice automation.
Our goal is to make developers' lives easier and businesses smarter.
Updated 3 months ago